Om de invloed van verschillende contactpunten in een klantreis te bepalen, is het data-driven attributiemodel binnen Google Analytics een interessante mogelijkheid. In dit artikel wordt uitgelegd hoe dit model waarde toekent, aan de hand van een praktijkvoorbeeld.
Het data-driven attributiemodel kent vanuit de beschikbare data waarde toe aan contactpunten, door te evalueren in welke mate het contactpunt bijdraagt aan de conversie. Binnen Google Analytics wordt dit berekend op basis van de Shapley Value Methode. Met een single touch model zoals het ‘laatste niet-direct klik’ attributiemodel wordt de conversie toegekend aan maar één kanaal. Bij het data-driven attributiemodel kan de conversie kan over meerdere kanalen worden verdeeld en wordt de verdeling van de conversie bepaald aan de hand van daadwerkelijk vergaarde data.
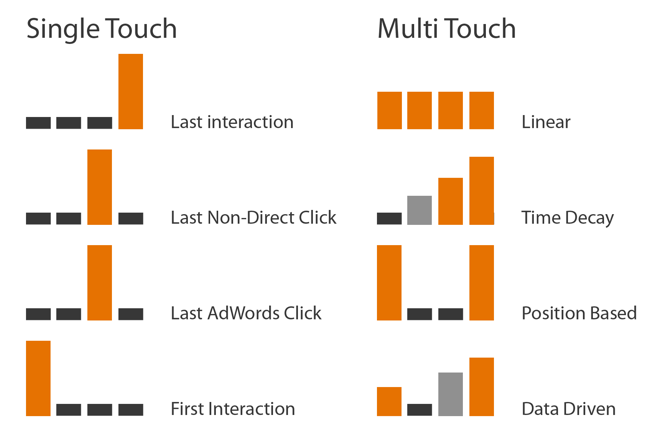
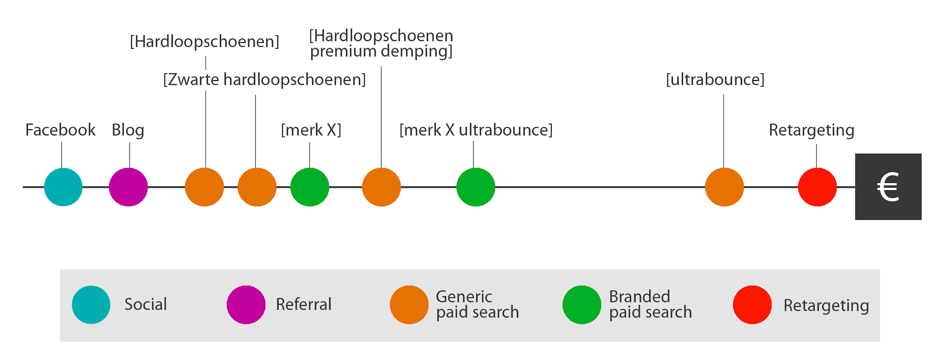
Afb. 1: attributiemodellen
Een voorbeeld van een customer journey
Stel je voor dat je tijdens het scrollen door je Facebook timeline een advertentie tegenkomt met nieuwe hardloopschoenen. Een paar dagen later lees je een blog met daarin een aantal sportoutfits met schoenen van dit merk.
Vervolgens besluit je op je vrije avond na het sporten op zoek te gaan naar nieuwe hardloopschoenen, waarbij je achtereenvolgens op de termen ‘hardloopschoenen’, ‘zwarte hardloopschoenen’ en een specifieke merknaam voor sportschoenen zoekt. Hierdoor kom je terecht op pagina’s met veel verschillende schoenen, al weet je nog niet precies wat je zoekt. Je besluit de zoektocht even te staken.
Na twee dagen besluit je na een rondje hardlopen weer verder te gaan met zoeken. Je huidige paar schoenen rent toch niet zo lekker meer. Je wil dan ook graag hardloopschoenen met een goede demping en zoekt op ‘hardloopschoenen premium demping’.
Je komt vervolgens een model sportschoenen tegen dat jouw interesse wekt en je zoekt op dit model schoenen via ‘merk X ultrabounce’. Aangezien je nu niet in de gelegenheid bent om deze te kopen, besluit je nog even te wachten met de aankoop.
Weer twee dagen later zit je ‘s ochtends in de trein, wanneer je je beseft dat je de schoenen nu wel echt moet kopen, wil je de schoenen nog kunnen inlopen voor de volgende hardloopwedstrijd. Je zoekt op ‘ultrabounce’, want dat was het model waar je interesse in had. Maar dan kom je een vriend tegen in de trein en vergeet je dat je aan het shoppen was.
Wanneer je ‘s avonds opnieuw in de trein zit en door de Facebook timeline scrollt, zie je ineens de schoenen die je ‘s ochtends had bekeken. Je besluit de schoenen nu wel meteen te bestellen, zodat je de schoenen nog op tijd binnen hebt voor je volgende hardloopsessie. Aankoop gedaan!
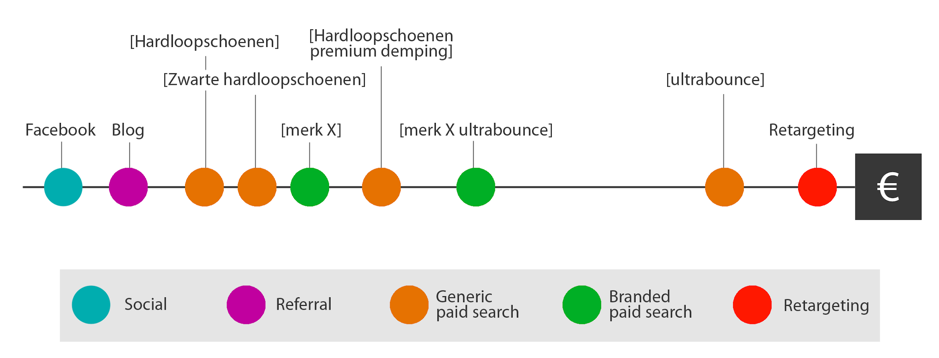
Afb. 2: Voorbeeld conversiepad
Aan de hand van dit voorbeeld (samengevat in afbeelding 2) zijn er verschillende vragen die je stelt wanneer je met online marketing voor het schoenenmerk bezig bent. Hoe waardevol is elk touchpoint binnen deze customer journey? En wat voor invloed heeft het als een van deze contactpunten niet op zou zijn getreden? Hoeveel waarde voegt het artikel op de blog toe? Om daar antwoord op te krijgen is per touchpoint de conversiewaarde van groot belang.
De waardetoekenning van data-driven attributie
De vraag is nu: hoe wordt een data-driven attributiemodel (en daarmee de waardetoekenning) bepaald? Bij het data-driven attributiemodel wordt de waarde proportioneel bepaald, door het weglaten van het contactpunt in het conversiepad. Bijvoorbeeld: wat is de verandering in de conversieratio wanneer bezoekers niet met display advertenties in aanraking gekomen zijn? Dit wordt ook wel een counterfactuele analyse genoemd.
Om het gehele data-driven attributiemodel samen te stellen worden vier lagen doorlopen: (1) exposure, (2) frequency, (3) recency en (4) frequency at each value of recency. Om deze vier lagen uit te leggen wordt gebruik gemaakt van de voorbeeldsituatie met de schoenen. Hierin komen meerdere contactpunten voor die verdeeld zijn over display advertising, generic paid search, branded paid search, e-mail en retargeting (zie afbeelding 2).
Laag 1 – Exposure
In de eerste laag wordt waarde toegekend op basis van de verandering van de conversieratio wanneer het kanaal zich niet voordoet in het conversiepad. Het voorbeeld van het kopen van schoenen levert een conversieratio van 5 procent op.
Stel dat in dit conversiepad generic paid search niet plaatsvindt, dan zou het om een conversieratio van 2,5 procent gaan, gezien de beschikbare data. Er wordt in dit geval een waarde van 2,5 procent toegekend aan generic paid search (5 procent minus 2,5 procent), voor het totaal van de contactpunten van dit kanaal. Generic paid search komt in dit conversiepad vier keer voor, dus wordt er per contactpunt (2,5 procent gedeeld door vier) 0,625 procent toegeschreven.
Pad:

Counterfactual:

Na berekening exposure:

Afb. 3: Exposure waardeberekening
Hetzelfde proces wordt vervolgens voor elk kanaal doorlopen. Hierna worden scores genormaliseerd (afbeelding 4), zodat het uiteindelijke pad uitkomt op een totale waarde van 1 (ook wel 100 procent).
Genormaliseerd:
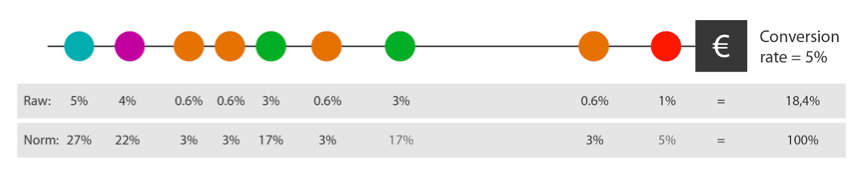
Afb. 4: Genormaliseerde exposure waardeberekening
Laag 2 – Frequency
In deze laag wordt de waarde gebaseerd op hoe de mogelijkheid voor een conversie verandert als een contactpunt van hetzelfde soort kanaal zich een bepaald aantal keer voordoet. In het voorbeeld (afbeelding 5) levert vier keer generic paid search in het pad een conversieratio op van 5 procent. Wanneer deze maar drie van de vier keer voorkomt, is het conversieratio 4 procent. Dit wil zeggen dat de verandering 1 procent is door het weglaten van de vierde keer generic paid search.
Pad:

Counterfactual:

Afb. 5: Frequency waardeberekening
Laag 3 – Recency
In de derde laag wordt waarde toegekend op basis van het voordoen van het contactpunt in een specifiek tijdsbestek. Als generic paid search contactpunten worden weggehaald uit een deel van het pad (in dit geval recency 5-7), verlaagt het conversieratio met 1,5 procent (zie afbeelding 6). Bij recency zijn bepaalde ranges samengesteld, bijvoorbeeld 5-7 dagen, om gebrek van data te reduceren en waarschijnlijkheid te vergroten. Doordat het contactpunt op een ander moment plaatsvindt, kan de impact op de eindconversie verschillen (zie afbeelding 6).

Pad:
Counterfactual:

Na berekening recency:

Afb. 6: Recency waardeberekening
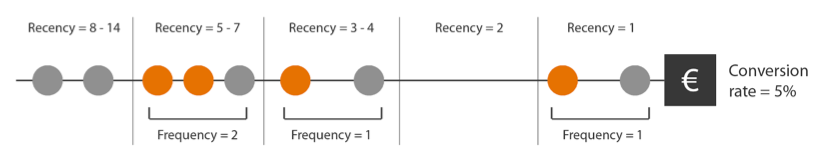
Laag 4 – Frequency at each value of recency
In de laatste laag wordt waarde toegekend op basis van het aantal keer dat een contactpunt met een kanaal zich voordoet binnen een bepaald tijdsbestek. Als generic paid search tweemaal voorkomt binnen de recency van 5-7 zorgt dit voor een conversieratio van 5 procent. Wanneer generic paid search eenmalig voorkomt binnen dezelfde recency, zorgt dit voor een conversieratio van 4 procent.
Het toevoegen van het contactpunt generic paid search binnen het tijdsbestek 5-7 zorgt dus voor een verhoging van het conversieratio van 1 procent (zie afbeelding 7). Net als bij recency, kan bij frequency at each value of recency de waarde per contactpunt verschillen (zie afbeelding 7).
Pad:
Counterfactual:

Na berekening frequency at each level of recency:

Afb. 7: Frequency at each value of recency waardeberekening
Impact van het toepassen van het data-driven attributiemodel
Kiezen voor een ander attributiemodel is overigens niet simpelweg het aanklikken van een ander model. De keuze voor het data-driven attributiemodel vraagt om een andere kijk op het conversiepad en daarmee om een consequente en doordachte implementatie.
In dit artikel wordt vooral beschreven hoe het data-driven attributiemodel werkt, maar daarnaast is het belangrijk om bewust te zijn van de impact op andere aspecten. Hierbij kun je denken aan veranderingen in de data, de manier van analyse en de samenwerking tussen verschillende contactpunten binnen de customer journey.
Een voorbeeld is dat er al een pad is gestart, maar dat de conversie nog niet heeft plaatsgevonden. Binnen Google Analytics heet dit ook wel het lookback window, die standaard wordt ingesteld op 30 dagen. In deze periode is er dus al wel een pad gestart, maar heeft de conversie nog niet plaatsgevonden, dus deze wordt nog niet meegenomen in de berekening. Het is belangrijk om nog een maand te wachten met analyseren voordat er conclusies worden getrokken over de prestaties, zodat je ook deze conversies meeneemt. Zo kun je vanaf 1 mei gaan analyseren wat er in de maand maart is gebeurd.
Om te kijken wat het verschil is tussen je huidige model en het data-driven model kun je binnen Google Analytics gebruik maken van de Model Comparison Tool.
Waarde verdelen over customer journey
In vergelijking met last non-direct click geeft het gebruik van het data-driven attributiemodel een ander beeld. Met behulp van het last non-direct click zou alle waarde van het conversiepad van het voorbeeld worden toegeschreven aan de remarketing, de laatste klik. Nu, door middel van het data-driven attributiemodel, wordt deze waarde verdeeld over de verschillende stappen in de customer journey, waaronder generic paid search.
Hierdoor is er veel meer mogelijk wat betreft het inzichten verwerven middels data. Echter is de keuze voor een data-driven attributiemodel niet zomaar het aanklikken van een ander model. Het vraagt om een andere manier van kijken naar het conversiepad en de data, wat vervolgens weer kan zorgen voor andere discussies omtrent de inzet van kanalen en het gebruik van contactpunten.
~ Dit artikel verscheen eerder op Emerce en Orangevalley. Als auteur plaats ik deze dus nogmaals door op mijn eigen website. ~